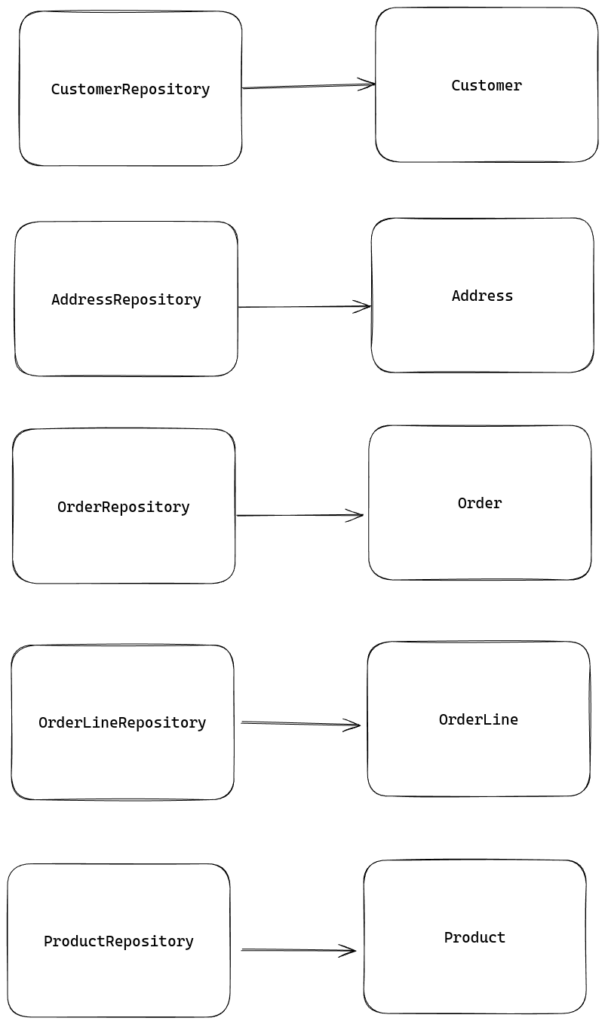
Repository per entity
The usual approach to accessing data is to have a repository and entity per database table. Directly mapping the database model to the business model. Many documentation pages of many different ORM’s use this approach in their examples. And usually this is a fine, and nice way of working with data. This however becomes somewhat harder to work with when we’re dealing with large, enterprise software, with many business validation rules.
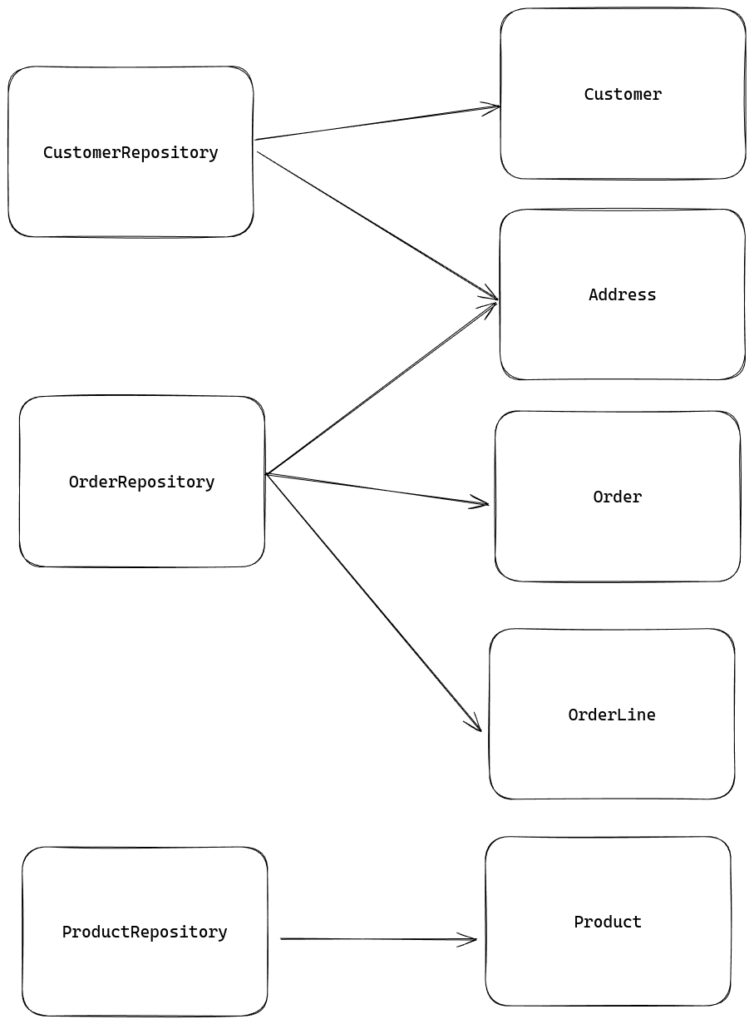
Moving towards aggregate roots
Having a repository per database entity has some negative implications. We could, for example change an Address of a Customer without adhering to the customers business rules. Perhaps we have a rule which states a Customer cannot change it’s address more than once per month.
Aggregate roots promise to solve this issue by having only one entry point per “cluster” of database entities. It can validate the preconditions before setting the address, or check the complete aggregate state before saving it to the database model.
It can only do this when the entire aggregate is loaded. This is where repositories in the DDD sense come in. Instead of loading each entity from the aggregate seperately, DDD repositories should load the entire cluster using JOINs (for example), leaving us with a completely loaded and validatable tree of data entities.
This does have a performance impact, and require some additional complexity to solve. Lazy loading related entities could be a solution.
DAO
So, how should repositories load their data, and how should we load data when using the AR is overkill? This is where Data Access Objects (DAO) come in, and pretty much take over the role of the original approach to repositories. These are objects to access the database, these could be ORM repositories. When using ORM repositories as DAO, you should name them Dao, clearly seperating the data model access from the domain model access